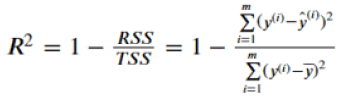H2机器学习概述
H3什么是机器学习
我们可以将模型理解为一个函数,输入模型的数据,我们称为训练数据。由训练数据来确定函数的参数的过程就叫训练数据(其实就是解方程)。
通过不断训练,我们最终会得到一个合适的模型,从而可以对未知的数据先进行预测。其实这过程和咋们人类学习过程十分类似,只不人的认知与判断是通过经验得到,而机器是通过数据得到。
其中,用于训练模型得到的每条数据,我们成为一个样本,而样本中的每个属性,我们称为特征,每个样本的目标输出值,我们称为标签(监督学习),我们习惯使用 x 来表示特征,习惯使用 y 来表示标签。
其实,咋们在初中就会训练模型了,比如算一道已知两点求直线方程的数学题,这类题目已经包括了机器学习的 2 个重要步骤:
- 训练
- 预测
正如大家所感受的那样,机器学习就是一个类似解方程的过程。然而,现实中的数据不可能像求直线方程那么简单,模型也不可能总是通过肉眼能观察出来,这时就需要咋们通过机器学习算法来进行建模了。
H3机器学习应用场景
- 语音识别技术、自然语言处理( Siri ,小娜,小度,小艾同学)
- 人脸识别(张学友演唱会上逃犯落网)
- 汽车无人驾驶技术(百度 Apollo)
- 专家系统(AlphaGo)
- 推荐系统(电商)
- 搜索引擎(利用历史点击数据把用户经常点击的结果排在前面)
- 各种预测系统(天气预测,足球预测)
H3机器学习与人工智能
**人工智能(Artificial Intelligence, AI)**是计算机科学的一个分支,目的是让计算机能够像人一样,对外界环境做出反应
机器学习(Machine Learning, ML),正是实现人工智能的一种方式。
**深度学习(Deep Learning, DL)**是一种机器学习技术,基于神经网络,适用于处理音频、视频、语言理解等方面。
H3机器学习分类
机器学习的问题分为监督学习和非监督学习两大类:
-
监督学习( supervised learning ):学习样本中有标签,好比有老师告诉你正确答案
- 分类(classification)输出为有限的离散型变量,比如预测明天的天气类型: 晴天
- 回归(regression)输出为连续型变量,比如预测明天的温度: 8-25°C
常用的监督学习算法 :线性回归 、逻辑回归 、决策树 和 SVM(支持向量机)
-
无监督学习(unsupervised learning):学习样本中无标签,靠机器观察自学,自己找模式和特征
-
聚类(clustering)
-
降维(dimensionality reduction)
常用非监督学习算法:K means、DBScan、PCA
-
H3机器学习流程

数据预处理:
数据集成:合并来自不同数据源的数据、处理冗余数据
数据清洗:缺失值、异常值
特征工程:
特征选择:通过各种统计和模型评分等筛选出合适的
特征特征变换:将类别型特征转换为数值型特征
特征组合:结合业务数据,两两组合一阶离散特征形成高阶组合特征
特征降维:PCA、LDA 等算法减少特征个数
特征归一化:消除数据特征之间的量纲影响,把特征值转变控制在 [0,1] 的区间
数据建模:
选择模型 → 训练模型 ↔ 评估模型 → 部署模型
处理类型型特征常用编码方式:
- 序号编码(Ordinal Encoding) 通常用于处理类别间具有大小关系的数据。比如学历分为了专科、本科、硕士三档,那么 用 3 表示 硕士、 2 表示 本科、 1 表示 专科,转换后依然保留了大小关系。
- 独热编码(One hot Encoding,用得较多) 通常用于处理类别间不具有大小关系的特征。比如血型,一共有 4 个取值( A、B、AB、O ),独热 编码会把血型变成一个 4 维稀疏向量, A 型血 →(1, 0, 0, 0),B 型血 →(0, 1, 0, 0),AB 型血 → (0, 0, 1, 0),O 型血 →(0, 0, 0, 1)
模型评估:
-
留出法(Holdout)
它将原始的样本集划分为训练集和测试集两部分:比如 70% 用于模型训练, 30% 用于模型评估测试。缺点就是评估效果与原始分组有关系。为了消除随机性,就引入了“交叉检验”的思想
-
交叉检验(Cross Validation)
- 𝑘 折交叉验证(𝑘 𝑓𝑜𝑙𝑑):首先将全部样本划分为 𝑘 个大小相等的样本子集;依次遍历这 𝑘 个子集,每次把当前自己作为验证集,其余所有子集作为训练集;最后 把 𝑘 次 评估指标的平均值作为最终评估指标, k 经常取 10 。
- 留一验证( 𝑙𝑒𝑎𝑣𝑒 𝑜𝑛𝑒 𝑜𝑢𝑡):每次留下一个样本作为验证集,其它所有样本作为训练集。如果有 𝑘 个样本,则需要训练 𝑘 次,测试 𝑘 次。留一法计算最繁琐,但样本利用率最高。适合于小样本的情况。
-
自助法(Bootstrap)
对于总数为 𝑛 的样本集合,进行 𝑛 次有放回的随机抽样,被抽中的样本放入训练集,最终训练集的大小也是 𝑛。𝑛 次采样过程中,有的样本会被重复抽中,有的从未被抽中,将这些从未被抽中的样本作为测试集。
回归模型常用评估指标:
-
MSE(Mean Squared Error)
平均平方误差,为所有样本误差(真实值与预测值之差)的平方和,然后取均值
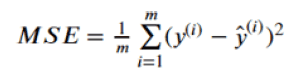
-
RMSE(Root Mean Squared Error)
平均平方误差的平方根,即在 MSE 的基础上,取平方根
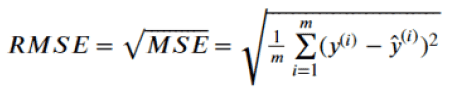
-
MAE(Mean Absolute Error)
平均绝对值误差,为所有样本误差的绝对值和
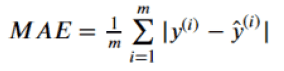
-
R^2
决定系数,用来表示模型拟合性的分值,值越高表示模型拟合性越好,最高为 1,可能为负值